1.3 Large Language Models In Biology#
Language models are systems designed to work with human language by learning patterns from lots of text. In simple terms, they try to predict what comes next in a sentence, which lets them do things like finish your sentences, answer questions, translate text, or write entire paragraphs. They are trained on large datasets and they learn grammar, meaning, and even bits of general knowledge through training. Instead of following strict rules, they rely on patterns they’ve seen before, which makes them flexible and surprisingly good at handling all kinds of language tasks.
Language models were originally developed for natural language processing, but the same principles can be applied to biological sequences such as DNA, RNA, and proteins. In this setting, sequences of amino acids or nucleotides are treated similarly to sequences of words in a sentence, allowing models to learn patterns and relationships within biological data.
Many modern AI models used in biology such as AlphaFold [NZLJ22] and ESM2 [LAR+23] are sequence-based language models. These models can also be considered foundation models, as they are trained on very large datasets and can be adapted to a wide range of downstream biological tasks.
1.3.1 Transformers: The Architecture Behind Modern LLMs#
Most modern natural language models, including those in biology, are built using a neural network architecture called the “transformer” [VSP+17].
Before transformers, many sequence models relied on architectures such as recurrent neural networks (RNNs) [RHW86] that processed sequences one element at a time. While effective, these models struggled to capture long-range relationships within sequences.
Note
The attention mechanism in Transformers address the limitation in capturing long-range relationships.
Attention allows the model to examine all positions in a sequence simultaneously and determine which elements are most relevant to one another. For example, in a protein sequence, the model can learn relationships between amino acids that are far apart in the sequence but may interact in the folded structure.
Because transformers process sequences in parallel and capture long-range dependencies effectively, they have become the dominant architecture for modern language models.
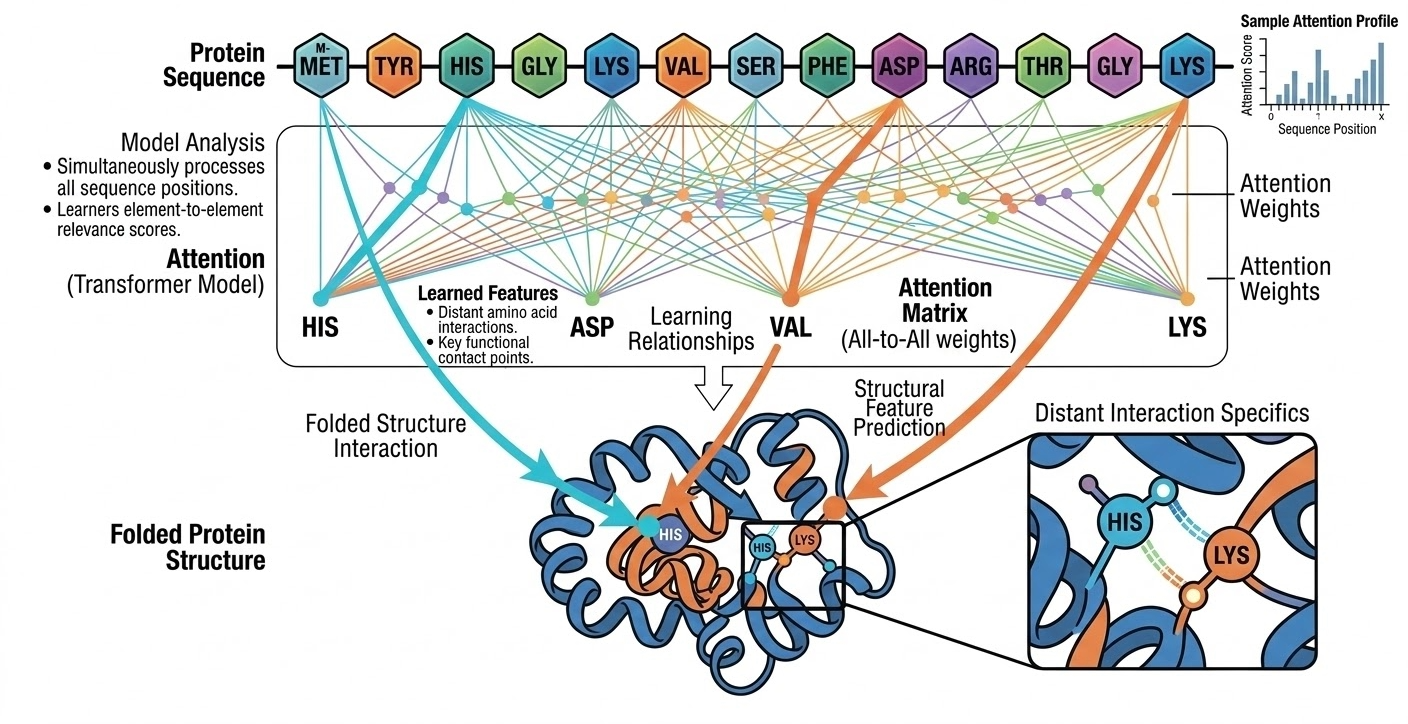
Fig. 4 Figure 1.3.1: Attention mechanism in transformers allow the model to learn relationships between amino acids that are far apart. (Created with gemini-3.1-flash-image-preview)#
1.3.2 Training Language Models#
Language models are typically trained using a strategy known as self-supervised learning. Training an LLM is less like “teaching a chatbot facts” and more like building a very large, very flexible pattern-recognizer, then gradually steering it toward helpful behaviors.
The first stages of training are known as pre-training and fine-tuning. For conversational language models, an additional step called Reinforcement Learning from Human Feedback (RLHF) is often used.
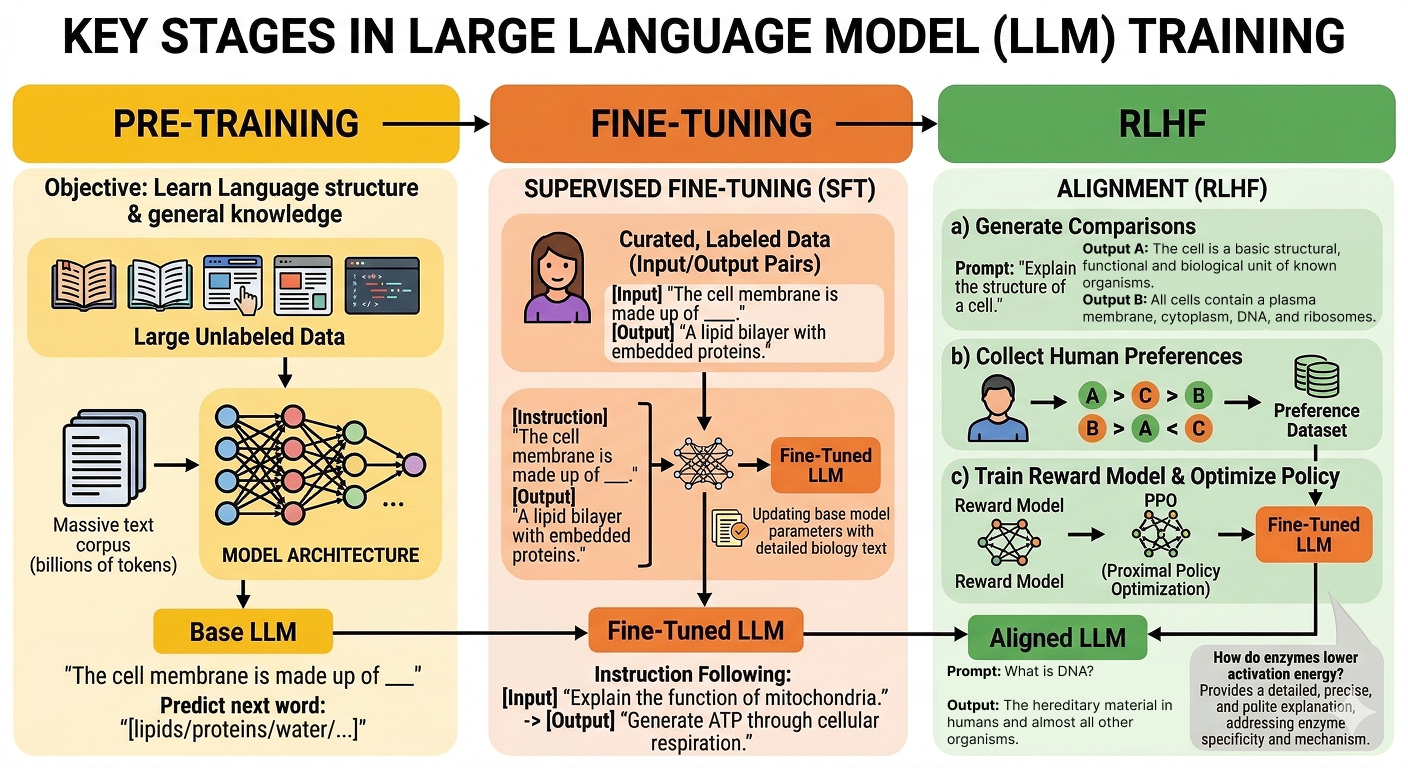
Fig. 5 Figure 1.3.2: Training an LLM is a multi-step process: pre-training, fine-tuning, and RLHF. These steps allow large language models to first learn general patterns from massive datasets and then become more specialized and aligned with human expectations. (Created with gemini-3.1-flash-image-preview)#
Together, pre-training, fine-tuning, and RLHF allow LLMs to first learn general patterns from massive datasets and then become more specialized and aligned with human expectations.
Pre-training#
Pre-training is the first stage in training a language model. During this stage, the model is trained on very large collections of sequences. These sequences can be natural language (i.e. sequences of words), protein sequences (i.e. sequences of amino acids), DNA sequences (i.e. sequences of nucleotides), or other sequential data. A foundation model trained only on protein sequences is known as a Protein Language Model (PLM).
Here, the model learns general statistical patterns present in the data. Think of these patterns as a model learning the “rules in biology”. The goal is to predict the next token (next amino acid, next nucleotide etc.) given a prior sequence. One advantage of pre-training is that it does not require manually labeled data. So it is possible to train models on extremely large datasets.
As pre-training is typically performed using self-supervised learning, the model learns by solving “prediction tasks” that are automatically derived from the data itself. These prediction tasks are known as training objectives. The objective defines what the model is asked to predict and provides the learning signal used to update the model’s parameters.
Two common training objectives are used in language models.
1) Next-token prediction
Here, the model learns to predict the next token (element) in a sequence given the elements that come before it. During training, the model repeatedly observes partial sequences and attempts to predict the next token.
For example if you’re working with an amino acid sequence, the model learns to predict the next amino acid. Read more on tokens here.
M A D K T L E V K → ?
2) Masked token prediction
Another common objective is masked token prediction, also known as masked language modeling. In this approach, some tokens in the sequence are randomly hidden, and the model must predict the missing elements using the surrounding context [DCLT19]. This objective is commonly used in autoregressive language models, such as GPT-style models.
Here the model must infer the missing amino acid in the given sequence.
M A D [MASK] T L E V K
Correct prediction: K
By training the model to predict either the next or the masked token of millions or billions of sequences, the model gradually learns “patterns” in the sequences. In natural language, this includes grammar and semantic relationships between words. In biological sequences, the model learns signals related to protein structure, evolutionary constraints, and functional motifs [GTC+21] based on the training data.
Fine-tuning#
After pre-training, language models can be adapted to specific tasks through a process known as fine-tuning. During fine-tuning, the pre-trained model is further trained on a smaller, task-specific dataset. Unlike pre-training, these datasets often contain labeled examples, where the correct output for each input is known [GTC+21, LSX+22].
The purpose of this step is to teach the model to specialize in particular applications while retaining the model. For example, a protein language model that has been pre-trained on millions of protein sequences can be fine-tuned to perform tasks such as predicting protein function, identifying binding sites, or estimating the effects of mutations. Compared to pre-training, fine-tuning typically requires much less data and compute.
Reinforcement Learning from Human Feedback (RLHF)#
For many conversational AI systems, an additional training stage called RLHF is used to improve the quality and safety of model responses [OWJ+22].
In RLHF, human evaluators review multiple outputs generated by the model and rank them according to criteria such as helpfulness, accuracy, and clarity. These rankings are then used to train a reward model that scores model outputs. The language model is subsequently optimized to produce responses that receive higher reward scores.
This process helps align the model’s behavior with human expectations and improves its ability to generate responses that are useful and safe in real-world applications.
1.3.3 Examples of foundational models in biology#
The table below provides a comparative overview of several major foundation models used in biological research.
Model Name |
Type |
Architecture |
Key Application |
Scale / Data |
|---|---|---|---|---|
ESM-2 |
Protein |
Transformer Encoder (BERT-style) |
Structure prediction, variant effect prediction, representation learning |
Up to 15B parameters; trained on ~65M UniRef sequences (pqac-00000032, pqac-00000034, pqac-00000039) |
ESMFold |
Protein |
ESM-2 + Folding Trunk |
Atomic-level protein structure prediction from single sequence (no MSA) |
3B to 15B parameters; trained on PDB + 12M AlphaFold predictions (pqac-00000033, pqac-00000036) |
AlphaFold2 |
Protein |
Evoformer + Structure Module |
High-accuracy structure prediction using Multiple Sequence Alignments (MSAs) |
Trained on PDB; utilizes large MSA databases (BFD, MGnify) (pqac-00000031, pqac-00000036) |
DNABERT / DNABERT-2 |
Genomic |
Transformer Encoder |
Promoter identification, splice site prediction, transcription factor binding |
Human genome; DNABERT-2 uses BPE tokenization and multi-species data (pqac-00000024, pqac-00000029) |
Enformer |
Genomic |
Transformer with long-range attention |
Predicting gene expression from sequence, enhancer-promoter interactions |
Long context window (100kb); trained on human/mouse genome data (pqac-00000026, pqac-00000029) |
HyenaDNA |
Genomic |
Hyena hierarchy (Long Convolution) |
Modeling long-range genomic patterns, variant classification |
Up to 1M token context window; trained on human reference genome (pqac-00000026, pqac-00000029) |
scGPT |
Single-Cell |
Generative Transformer |
Cell type annotation, perturbation prediction, batch correction |
Trained on >10M single-cell profiles (pqac-00000024, pqac-00000026) |
Geneformer |
Single-Cell |
Transformer |
Dosage sensitivity, chromatin dynamics, gene network modeling |
Trained on ~30M single-cell transcriptomes (pqac-00000026) |
ProtGPT2 |
Protein |
Transformer Decoder (GPT-style) |
De novo protein sequence generation |
Trained on UniRef50; 738M parameters (pqac-00000027, pqac-00000029) |
ProGen |
Protein |
Transformer Decoder (Conditional) |
Controllable protein sequence generation |
Trained on ~280M protein sequences with taxonomic/functional tags (pqac-00000026) |
ProteinBERT |
Protein |
Transformer Encoder (BERT-style) |
Protein function prediction, GO term classification |
Trained on UniRef90 + Gene Ontology annotations (pqac-00000024, pqac-00000029) |
1.3.4 Additional Reading#
Hugging Face LLM Course: Highly recommended! A great resource for getting started on LLMs
References#
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: pre-training of deep bidirectional transformers for language understanding. ArXiv, pages 4171–4186, 2019. URL: https://doi.org/10.48550/arxiv.1810.04805, doi:10.48550/arxiv.1810.04805.
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare, 3:1–23, Oct 2021. URL: https://doi.org/10.1145/3458754, doi:10.1145/3458754.
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Salvatore Candido, and Alexander Rives. Evolutionary-scale prediction of atomic-level protein structure with a language model. Mar 2023. URL: https://doi.org/10.1126/science.ade2574, doi:10.1126/science.ade2574.
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. Biogpt: generative pre-trained transformer for biomedical text generation and mining. Briefings in bioinformatics, Sep 2022. URL: https://doi.org/10.48550/arxiv.2210.10341, doi:10.48550/arxiv.2210.10341.
Ruth Nussinov, Mingzhen Zhang, Yonglan Liu, and Hyunbum Jang. Alphafold, artificial intelligence (ai), and allostery. The Journal of Physical Chemistry. B, 126:6372–6383, Aug 2022. URL: https://doi.org/10.1021/acs.jpcb.2c04346, doi:10.1021/acs.jpcb.2c04346.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and others. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.