1.1 Evolution of AI#
This page provides a background on AI. You may skip to Chapter 2 or Chapter 3 to see more hands-on applications.
From genome sequencing to single-cell transcriptomics to high-content imaging and protein structure prediction, modern biology generates data at a scale and complexity that exceeds traditional analytical approaches. Artificial intelligence (AI) has emerged as a powerful set of tools for extracting patterns, generating hypotheses, and accelerating discovery from biological data.
While AI can feel like magic, it is only a collection of statistical principles, mathematical models, and computational tools. These must be understood, applied and evaluated carefully, especially in high-stakes scientific contexts.
We’ll begin with the history and basic ideas behind AI—how the field started, how it evolved, and the key concepts that shape modern systems today. Understanding this background helps demystify AI and gives us the tools to think critically about how these systems work.
From there, we’ll shift toward practical applications of modern AI in biology, focusing on large language models (LLMs) and AI agents. We’ll explore how these tools can be used in everyday scientific workflows, with a particular focus on biological research. The goal is to move beyond the buzz words and understand how AI can actually help scientists ask better questions, analyze data more efficiently, and accelerate discovery.
1.1.1 A Timeline#
Fig. 1 Figure 1.1.1: Evolution of AI (Created with gemini-3-flash-preview)#
1950s - Can Machines Think?: AI didn’t start with code; it started with a question. In the 1950s, scientists began to ask if machines could think. Alan Turing famously reframed the question into something more practical: instead of debating what “thinking” is, could a machine behave intelligently enough to be indistinguishable from a human? In the summer of 1956, a small group of researchers gathered at Dartmouth College for what would later be called the birth of Artificial Intelligence. John McCarthy coined the term “Artificial Intelligence” and proposed what he described as a “2-month, 10-man study” [MRS55]. The proposal was ambitious. It suggested that key aspects of intelligence, including learning, might be described so precisely that a machine could simulate them. The topics they outlined sound surprisingly modern: natural language processing, neural networks, abstraction, creativity, and the theory of computation.
1960s - From Big Dreams to Expert Knowledge: As the field matured, researchers realized that general intelligence was harder than it looked. By the late 1960s, the focus shifted. Instead of trying to build machines that could reason about everything, scientists started building systems that reasoned about very specific domains — chemistry, medicine, mathematics. The key insight was practical: AI systems worked much better when they were packed with expert knowledge. This gave rise to “expert systems”; programs such as MACSYMA: for symbolic mathematics, DENDRAL: for chemical structure inference and MYCIN: for clinical decision support [Sho86]. These systems didn’t “learn” in the modern sense. They encoded human expertise directly. And in scientific domains that approach worked surprisingly well. But it also revealed a bottleneck: extracting and formalizing expert knowledge was incredibly difficult. Building intelligence by hand was slow and brittle.
1990s - Let the Data Speak: By the 1990s, a new perspective gained momentum. Instead of hand-coding intelligence, maybe we could learn it from data. Statistical learning theory (SLT) provided a mathematical framework for understanding when learning from examples would generalize beyond the training data [Vap99]. This wasn’t just philosophical, it addressed a deep scientific question: When can we trust a model trained on finite data? Support Vector Machines (SVMs) emerged as one of the first widely used algorithms built directly from this theory. They showed that you could combine mathematical guarantees with practical performance. This era marked a shift from rule-based systems to data-driven learning. Instead of encoding expertise directly, we began building systems that could extract structure from data themselves. It was this shift that laid the groundwork for modern machine learning (ML) and eventually, the deep learning (DL) systems transforming biology today.
2010s - The Deep Learning Comeback: For a while, neural networks were out of fashion. They had been explored since the 1980s, but training large networks was difficult, datasets were small, and computers were slow. Many researchers shifted toward other approaches. Then three things changed at once: 1) We had massive datasets, 2) We had powerful GPUs, and 3) We had a few key algorithmic improvements. DL reframed AI problems as representation learning. Instead of hand-designing features, multilayer neural networks could learn hierarchical features directly from raw data — pixels, audio signals, sequences. The moment that made everyone pay attention came in 2012. A team led by Alex Krizhevsky trained a large deep convolutional neural network on the ImageNet dataset — about 1.2 million images across 1000 categories [KSH12]. Their model dramatically outperformed competitors in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The top-5 error rate dropped from 26.2% (runner-up) to 15.3%. That wasn’t a small improvement. It was a shock. The system — later known as AlexNet — relied on GPU training, rectified linear units (ReLUs), architectural depth, and dropout regularization. But more importantly, it showed that deep neural networks could scale — and that performance improved as data and compute increased [LBH15]. The lesson of the 2010s was clear: scale matters. With enough data and compute, neural networks could learn powerful representations directly from raw inputs.
2020s - Generative AI and Foundation Models: If the 2010s were about learning powerful representations, the 2020s became about learning general-purpose models. The key technical breakthrough that made this possible was the transformer architecture, introduced in 2017 [VSP+17]. Unlike earlier sequence models such as RNNs [RHW86], LSTMs [HS97], transformers relied on a mechanism called attention, which allowed models to weigh relationships between all parts of an input at once. This made them dramatically better at modeling long-range dependencies in language, code, and even biological sequences. Just as importantly, transformers scaled extremely well. As researchers increased model size, dataset size, and compute, performance improved in a surprisingly smooth and predictable way. This “scaling behavior” made it feasible to train very large models on massive datasets. Instead of training a separate model for each problem, researchers began pretraining large transformer models on vast corpora (text from the internet, millions of protein sequences, genomic data) and then adapting them to specific tasks through fine-tuning or prompting. These became known as foundation models. In natural language, this led to large language models capable of reasoning, summarizing, coding, and assisting with scientific writing.
1.1.2 AI in Science: From Data Overload to Discovery#
Modern biology (and science in general) is overflowing with data. We can sequence genomes at scale. We can measure gene expression in millions of single cells. We can generate high-content imaging datasets that capture cellular morphology in extraordinary detail. But there’s a catch: biological data is messy, high-dimensional, and often incomplete [OPV+17, RM24].
Many assays are destructive. Some measurements can’t be taken on the same cell. Others can’t be measured simultaneously at all [BS05, tWBOM16]. Time-series experiments are expensive. Perturbations are constrained. In practice, we observe fragments of a much larger biological system [US22]. So the challenge isn’t just generating data anymore, it’s stitching it together.
This is where AI has become essential. Machine learning methods like representation learning, generative modeling, and optimal transport allow us to integrate different data modalities, align measurements across conditions, and build models that infer what we cannot directly measure. In this sense, AI isn’t just analyzing biology, it’s filling in the missing pieces.
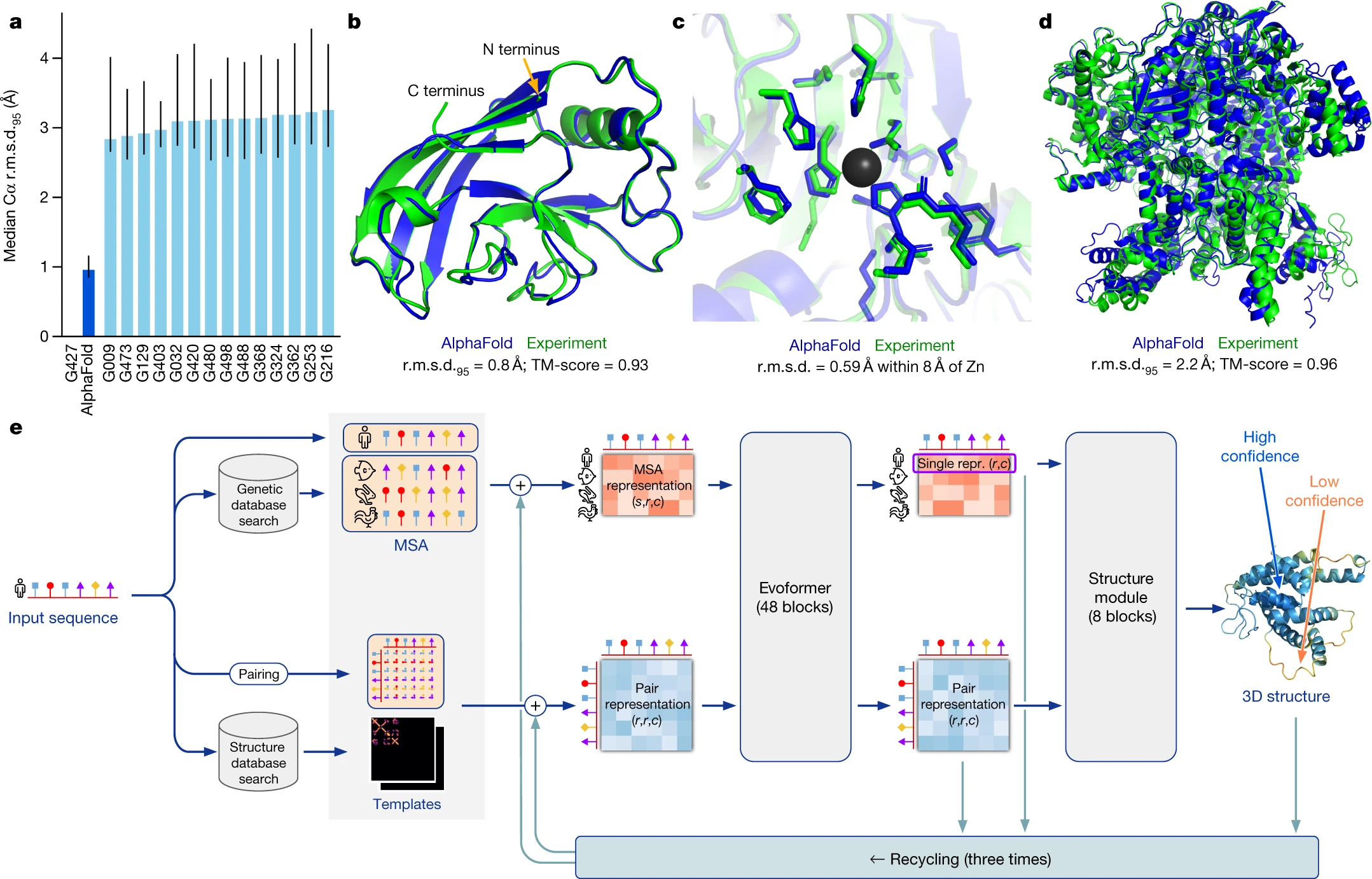
Fig. 2 Figure 2: The performance of AlphaFold on the CASP14 dataset [Copied from Jumper et al., 2021]#
AlphaFold is one example that demonstrates the impact of AI in biology [JEP+21]. Protein structure is foundational to understanding function and mechanism. But experimentally determining structure is slow, expensive, and feasible for only a fraction of known sequences. Using deep neural networks trained on structural and evolutionary data, AlphaFold demonstrated that protein structures could be predicted with near-atomic accuracy, even in cases where no close structural template exists [JEP+21]. Its performance in the CASP14 blind assessment made it clear that structure prediction had entered a new era.
This didn’t just solve a benchmark problem. It unlocked a new regime of large-scale structural bioinformatics. Suddenly, millions of proteins could be modeled computationally. Researchers could explore binding sites, generate hypotheses about function, and reason mechanistically at scale.
Zooming out, what’s happening in biology reflects a broader shift across the sciences. AI has evolved from early expert systems that encoded human knowledge, to statistically grounded learning frameworks that formalized generalization, to DL systems capable of automatically extracting task-relevant representations from massive datasets, to generating new sequences to optimize a specific activity [GKMJ22, NZLJ22].
AI has proven capable of extracting intricate patterns from large datasets in genomics, drug discovery, imaging, and beyond. The same methods that power image recognition and speech systems are now being adapted to understand genomes, proteins, and cellular systems.
1.1.3 Additional materials#
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
Chapter 4.1: AI glossary for more definitions.
Providing Feedback#
We’d love to hear from you! Whether you run into issues, have ideas for improving the tutorials, or want to suggest new topics, feel free to reach out.
Email us at: tutorials@futurehouse.org
References#
William Bialek and Sima Setayeshgar. Physical limits to biochemical signaling. Proceedings of the National Academy of Sciences, 102(29):10040–10045, 2005.
Joe G. Greener, Shaun M. Kandathil, Lewis Moffat, and David T. Jones. A guide to machine learning for biologists. Nature Reviews Molecular Cell Biology, 23:40–55, Sep 2022. URL: https://doi.org/10.1038/s41580-021-00407-0, doi:10.1038/s41580-021-00407-0.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, and others. Highly accurate protein structure prediction with alphafold. nature, 596(7873):583–589, 2021.
A. Krizhevsky, I. Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60:84–90, Dec 2012. URL: https://doi.org/10.1145/3065386, doi:10.1145/3065386.
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. May 2015. URL: https://doi.org/10.1038/nature14539, doi:10.1038/nature14539.
missing journal in mccarthy1955dartmouthworkshop
Ruth Nussinov, Mingzhen Zhang, Yonglan Liu, and Hyunbum Jang. Alphafold, artificial intelligence (ai), and allostery. The Journal of Physical Chemistry. B, 126:6372–6383, Aug 2022. URL: https://doi.org/10.1021/acs.jpcb.2c04346, doi:10.1021/acs.jpcb.2c04346.
Sergey Ovchinnikov, Hahnbeom Park, Neha Varghese, Po-Ssu Huang, Georgios A Pavlopoulos, David E Kim, Hetunandan Kamisetty, Nikos C Kyrpides, and David Baker. Protein structure determination using metagenome sequence data. Science, 355(6322):294–298, 2017.
Jeffrey A Ruffolo and Ali Madani. Designing proteins with language models. Nature Biotechnology, 42(2):200–202, 2024.
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
EH Shortliffe. Medical expert systems—knowledge tools for physicians. Unknown journal, 1986.
Pieter Rein ten Wolde, Nils B Becker, Thomas E Ouldridge, and Andrew Mugler. Fundamental limits to cellular sensing. Journal of Statistical Physics, 162(5):1395–1424, 2016.
Caroline Uhler and G. V. Shivashankar. Machine learning approaches to single-cell data integration and translation. Proceedings of the IEEE, 110:557–576, May 2022. URL: https://doi.org/10.1109/jproc.2022.3166132, doi:10.1109/jproc.2022.3166132.
V.N. Vapnik. An overview of statistical learning theory. IEEE transactions on neural networks, 10 5:988–99, Sep 1999. URL: https://doi.org/10.1109/72.788640, doi:10.1109/72.788640.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.